

はじめに
ここではC言語を通してコンピュータサイエンスの理解を深めていきます。
C言語はWebアプリケーションの開発において採用されることがほとんどないような言語ですが、いろんなプログラミング言語の元になっている言語です。
コンピュータが2進数で動作していることや、メモリ管理の実態がコードや実行結果から読み取りやすいので、開発には難しいとされる言語ですが、コンピュータサイエンスの理解を深めるには適しているといえるでしょう。
私自身、C言語はこれまでほとんど書いたことがないので詳しくはないですし、基本的な構文は他の言語と似ている箇所が多いので、構文の説明は省いていきます。
コンピュータサイエンスの理解に必要なところに焦点を当てて学習を進めていきます。
基本構文
さっそくですが、C言語で簡単な処理を実行してみましょう。実行環境自体はPCに最初から入っていると思いますので、作業ディレクトリを切って、書いていきましょう
拡張子は.cにしてファイルを作成します。ここではhello.cを作成しました。
#include <stdio.h>
int main(void)
{
printf("Hello, World!\n");
}それでは実行します。
そのままでは動作しないので、一度コンパイルをし、コンパイルによって作成されたファイルを実行にかけます。
$ make hello
$ ./hello
> Hello, World!Hello, World!をコンソールに出力するシンプルな処理でした。
初めてC言語を動作させる方には見慣れない箇所がいくつかあると思いますので、上から簡単に説明しておきます。
#include <stdio.h>こちらは依存ライブラリを読み込んでいます。stdio.hというヘッダーファイルがPCのどこかに実装され、用意されているので、これを読み込んでいます。これがないとprintf関数が未定義の関数になってしまいます。C言語でもいろいろ便利な関数は用意されていますが、includeはちゃんと明記しておく必要があるようです。
int main(void)メイン関数の定義を行っています。このファイルがエントリーポイントになっているときにmain関数が実行される仕様になっています。
intはこの関数が返す値を定義しています。今回はprintfしか関数内で行っていませんが、main関数は終了コードと呼ばれる暗黙の値を返します。その値はなにも定義しない場合、0になります。
使いみちはプログラムの実行中にエラーが発生して正常に終了しなかったときに、明示的にreturn 1などとして、終了コードを返すことで、コードの終了原因を知るヒントを出すことができます。
よく、コマンドを実行してexit code: 〜 とあるのはこのことですね。
Httpステータスコードと似たような役割ですが、別物です。
mainは関数名ですね。エントリーポイントになる特殊な関数名です。
(void)は引数の型です。voidは何も引数として受け取らないことを意味します。
コマンドラインでの実行時に引数を指定する場合は、int main(int argc, char *argv[])と書くことになります。そして、./hello [OPTION] と渡します
コンパイル
make helloでサクッとコンパイルして、./helloでコードをサクッと実行してもらいましたが、この裏側についても触れておきたいと思います。
まず、実行にあたってはhello.cを直接実行していません。make helloによって同じディレクトリ階層にhelloというファイルが作成され、そのファイルを実行しています。
helloファイルをテキストエディタで開こうとしてみると、
”The file is not displayed in the text editor because it is either binary or uses an unsupported text encoding.”
と言われ、警告がでるかと思います(vscode)警告が出ても開くとすると、えらく文字化けしたファイルになるかと思います。
このhelloファイルはマシンコードと呼ばれるコードが書いてあるファイルです。
マシンコードはバイナリ形式(0と1だけで書かれたもの)の命令文で書かれているコードで、コンピュータはこれを読み取って実行できます。エディタではこのバイナリ形式のマシンコードを開こうとするとASCIIやUnicodeに変換しようとするが、対応する文字が見つからないため、文字化けしてしまうというわけです。
hello.cというC言語からhelloというマシンコードに変換することをコンパイルといいます。
Cからマシンコードへはいきなりは変換されません。
①前処理 ②コンパイル ③アセンブル ④リンク
の順番をたどります。
①前処理では、include <stdio.h>などのライブラリのコードから処理の実行に必要なプログラムを取得してきます。そして、そこで実装されている関数を読み込みます。
②コンパイルでは、C言語をアセンブリコードと呼ばれる別のソースコードに変換します。次のようなコードです。
.file "hello.c"
.text
.section .rodata
.LC0:
.string "Hello, World!"
.text
.globl main
.type main, @function
main:
endbr64
pushq %rbp
movq %rsp, %rbp
leaq .LC0(%rip), %rdi
call puts@PLT
movl $0, %eax
popq %rbp
ret③アセンブルでは、生成したアセンブリコードをバイナリ形式のマシンコードに変換します。
④リンクでは、①で読み込んだライブラリを生成したマシンコードと結合させます。
これによってhelloファイルの完成です。
②でコンパイルの手順が出てきました。コンパイルは正確にはアセンブリコードに変換することを意味するのですが、この4つの手順を全てひっくるめてコンパイルとも表現されますし、実際その使われ方がされることの方がずっと多いです。この先、コンパイルを目にしたときは①〜④の全てのことを指すと理解していただいてよいでしょう。
メモリ
コンピュータの内部にはRAM(ランダム・アクセス・メモリ)と呼ばれるチップが入っています。
RAMはデータを保存するためには常に電力が必要なため、突然電力の供給がなくなるとRAMに入っていたデータは無くなってしまいます。(揮発性)ですが、データの取得は高速なのが特長です。
一方、コンピュータが情報を保存するためのものとして、ハードドライブやSSD(ソリッド・ステート・ドライブ)があります。こちらはデータの保存に電力は不要です。長期で保存するのに向いていますが、データの取得には時間がかかります。
実行中のプログラムはRAMで管理されます。
RAMにデータ(バイト)が格納されるときは無数のバイトごとのスペースが確保され、その中に収まるようなイメージです。

イメージでは100ほどのスペースしか確保されていませんが、実際は数十億バイトくらいはあります。
(macbook airの最小のメモリでも現在は16GBありますので、16億バイトです。16億マスのスペースが利用できます)
Cでは変数の型に応じて、その値を格納するために使われるバイト数が異なります。
コンピュータシステムによって実際に使用される容量は異なりますが、多くの環境では次の通りです。
| 型名 | 概要 | バイト数 |
| bool | 真偽値 | 1byte |
| char | 1文字の文字列 | 1byte |
| float | 浮動小数点数(小) | 4byte |
| double | 浮動小数点数(大) | 8byte |
| int | 整数(小) | 4byte |
| long | 整数(大) | 8byte |
次のように変数にintを格納する場合、RAMでは次のように値が格納されます。
#include <stdio.h>
int main(void)
{
int score1 = 72;
int score2 = 73;
int score3 = 33;
printf("Average: %f\n", (score1 + score2 + score3) / 3.0);
}

intは4byte消費するので一つのint変数につき、4つのマスを占有します。
次に文字列を見ていきましょう。
C言語における文字列は他の言語の文字列と少し異なり、文字列はcharの配列と捉えられます。
そのため、文字列を格納する際の定義は char name[] = "HI!" となります。
少し実装してみましょう。
#include <stdio.h>
int main(void)
{
char name[] = "HI!";
printf("%c, %c, %c", name[0], name[1], name[2]);
// H, I, !
}
name[]に入れた文字列を配列のインデックス番号の低い順に取り出して、出力します。
%cは取り出した値がchar型であることを示しています。
では、この%cを%iに変えてみます。%iは取り出した値をint型に変えるものです。
#include <stdio.h>
int main(void)
{
char name[] = "HI!";
printf("%i, %i, %i", name[0], name[1], name[2]);
// 72, 73, 33
}
すると、結果は72, 73, 33となりました。この3つの数字はASCIIコードにおいてその文字が割り当てられている数値です。(前回のテキスト表現を参照)
それでは、少し実験をしてみます。
name[]に入れている文字数が現在は3文字なため、0~2までを角カッコに入れていましたが、もっと数字を増やしていってみます。
#include <stdio.h>
int main(void)
{
char name[] = "HI!";
printf("%i, %i, %i, %i, %i", name[0], name[1], name[2], name[3], name[4]);
// 72, 73, 33, 0, -96
}
72, 73, 33, 0, -96が返ってきました。
まず、0についてです。
文字列がRAMに格納されるとき、charは1byteなので、/ H / I / ! /とそれぞれ格納されます。
ですが、このとき、すぐ隣のマスにも同じようにcharが来てしまうとどこでnameの文字を終了してよいのかわからなくなってしまいます。
そこでchar name[]と値を入れるときは、3文字入れるときは4byte使って値を保存します。そして、残りの1byteには「0」(NULL)を入れるのです。このNULLをみてこの変数の文字はここで終了していると判断できるようになります。
では-96はどうでしょう?もし実際に実行されている場合はみなさんは別の値が出ているかもしれません。この値はたまたまNULLの隣にあったRAMの値です。
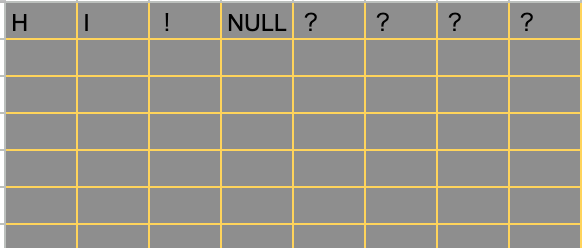
左からH・I・!・NULLを出力していき、その変数が管理すべき値は全て消化されたが、さらに横の値の?になっているところも参照されてその値が出ているのです。そして、この値は書き換えることができてしまいます。
さらに、この値はもしかしたらこのプログラムで管理している変数ではなく、全く別のプログラムが管理している変数の可能性もあります。
なので、ソースコードで管理している値以外の値を書き換えて、別の起動中のプログラムに悪影響を及ぼすことができてしまうのです。
これは非常に危険なのでC言語で実装するときには注意しなくてはいけません。
幸い、このような処理をコンパイルするとき、警告が出ます。
”hello.c:6:70: warning: array index 4 is past the end of the array (which contains 4 elements) [-Warray-bounds]”
まずこのような危険なコードを差し込めることを理解し、警告文をよく読んで危険なコードは避けるようにしましょう。
メモリは有限
メモリには何十億バイトも格納できるとはいえ、当然有限です。
ですが、普段コンピュータを利用している分にはメモリの管理はコンピュータ自身が使用していないデータはメモリから適宜削除するなどして適切に管理してくれているので、あまり意識することなく利用できます。
そんなメモリがやはり有限であるということを体験していきたいと思います。
#include <stdio.h>
int main(void)
{
float x = 1;
float y = 10;
printf("%f\n", x / y);
// 0.100000
printf("%.50f\n", x / y);
// 0.10000000149011611938476562500000000000000000000000
}
単純に1÷10を行ってその結果を出力しています。
最初の出力結果はfloatをそのまま出力しています。この結果は期待通り、0.1になってくれています。
その次の出力結果はfloatではありますが、50桁まで表示するようにしています。
すると、10桁目あたりから、予期しない数字が入ってきました。
これは浮動小数点精度の精度不足によるものです。
まず、コンピュータは2進法が採用されています。そして、私たちは10進法で生活しています。
10進法においては0.1は有理数ですが、2進法においては0.1は割り切れない数(無理数)になるのです。そのため、どこまでいっても計算を終えることができません。ですが、どこまでも計算を続けてしまうとあっという間にメモリ不足になってしまいます。これを回避するためにコンピュータは、どこかで見切りをつけて数を丸めて計算を終了させます。見切りをつけて計算を終了するので、その結果を人が見やすいように10進法に変換すると、0.1に近いけれど、でも0.1ではない値が返ってきてしまうのです。この現象自体は他のプログラミング言語においても見られる現象かと思います。
より大きなfloat型を扱ったり、小数第何位とかで四捨五入するなどをしてあげることでコントロールするようにしましょう。
コメント